




什么是网络爬虫?网络爬虫有什么用?

在大数据浪潮中,最值钱的就是数据,企业为了获得数据,处理数据,理解数据花费了巨大代价,使用网络爬虫可以最有效的获取数据。
什么是爬虫?
网络蜘蛛(Web spider)也叫网络爬虫(Web crawler),蚂蚁(ant),自动检索工具(automatic indexer),或者(在FOAF软件概念中)网络疾走(WEB scutter),是一种“自动化浏览网络”的程序,或者说是一种网络机器人。它们被广泛用于互联网搜索引擎或其他类似网站,以获取或更新这些网站的内容和检索方式。它们可以自动采集所有其能够访问到的页面内容,以供搜索引擎做进一步处理(分检整理下载的页面),而使得用户能更快的检索到他们需要的信息。
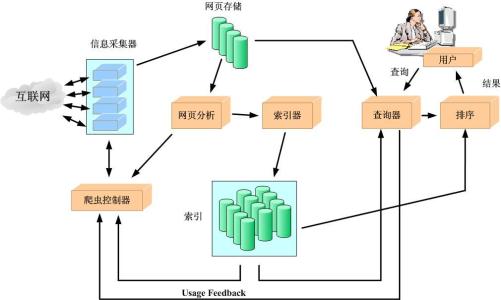
最常见的就是互联网搜索引擎,它们利用网络爬虫自动采集所有能够访问到的页面内容,以获取或更新这些网站的内容和检索方式。在网络爬虫的系统框架中,主过程由控制器、解析器、资源库三部分组成。控制器的主要工作是负责给多线程中的各个爬虫线程分配工作任务。解析器的主要工作是
下载信息,将信息中对用户没有意义的内容(比如网页代码)处理掉。资源库是用来存放下载到的数据资源,并对其建立索引。
假如你想要每小时抓取一次网易新闻,那么你就要访问网易并做一个数据请求,得到html格式的网页,然后通过网络爬虫的解析器进行过滤,最后保存入库。
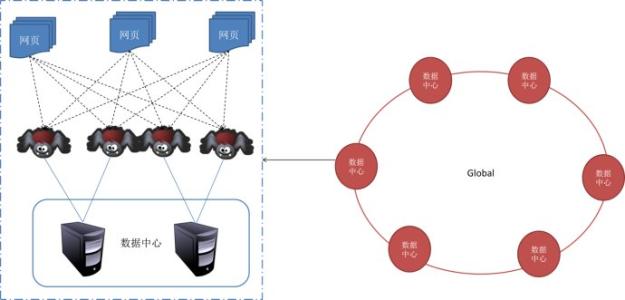
爬虫的工作原理
爬虫能做什么?
可以创建搜索引擎(Google,百度)
可以用来抢火车票
带逛
简单来讲只要浏览器能打开的,都可以用爬虫实现
网络爬虫的分类?
网络爬虫可以分为通用网络爬虫(General Purpose Web Crawler)、聚焦网络爬虫(Focused Web Crawler)、增量式网络爬虫(Incremental Web Crawler)和深层网络爬虫(Deep Web Crawler)。通用网络爬虫又称全网爬虫(Scalable Web Crawler),爬行对象从一些种子 URL(网络上每一个文件都有一个地址,即URL) 扩充到整个 Web,主要为门户站点搜索引擎和大型 Web 服务提供商采集数据。 由于商业原因,它们的技术细节很少公布出来。
聚焦网络爬虫(Focused Crawler),又称主题网络爬虫(Topical Crawler),是只爬行与主题相关网络资源的爬虫。它极大地节省了硬件和网络资源,保存的数据也由于数量少而更新快,还可以很好地满足一些特定人群对特定领域信息的需求。
增量式网络爬虫(Incremental Web Crawler)是指只爬行新产生的或者已经发生变化数据的爬虫,它能够在一定程度上保证所爬行的数据是尽可能新的,并不重新下载没有发生变化的数据,可有效减少数据下载量,及时更新已爬行的数据,减小时间和空间上的耗费。
深层网络爬虫(Deep Web Crawler)则可以抓取到深层网页的数据。一般网络页面分为表层网页和深层网页。 表层网页是指传统搜索引擎可以索引的页面,而深层页面是只有用户提交一些关键词才能获得的页面,例如那些用户注册后内容才可见的网页就属于深层网页。
学习爬虫技术势在必行:在现在竞争的信息化社会中,如何利用数据分析让自己站在信息不对称的一方,保持竞争优势,是数字工作者的必备技能。不过想飞之前总得先学会跑步,分析数据之前先首要学会爬数据与处理数据,才有有事半功倍之效。
